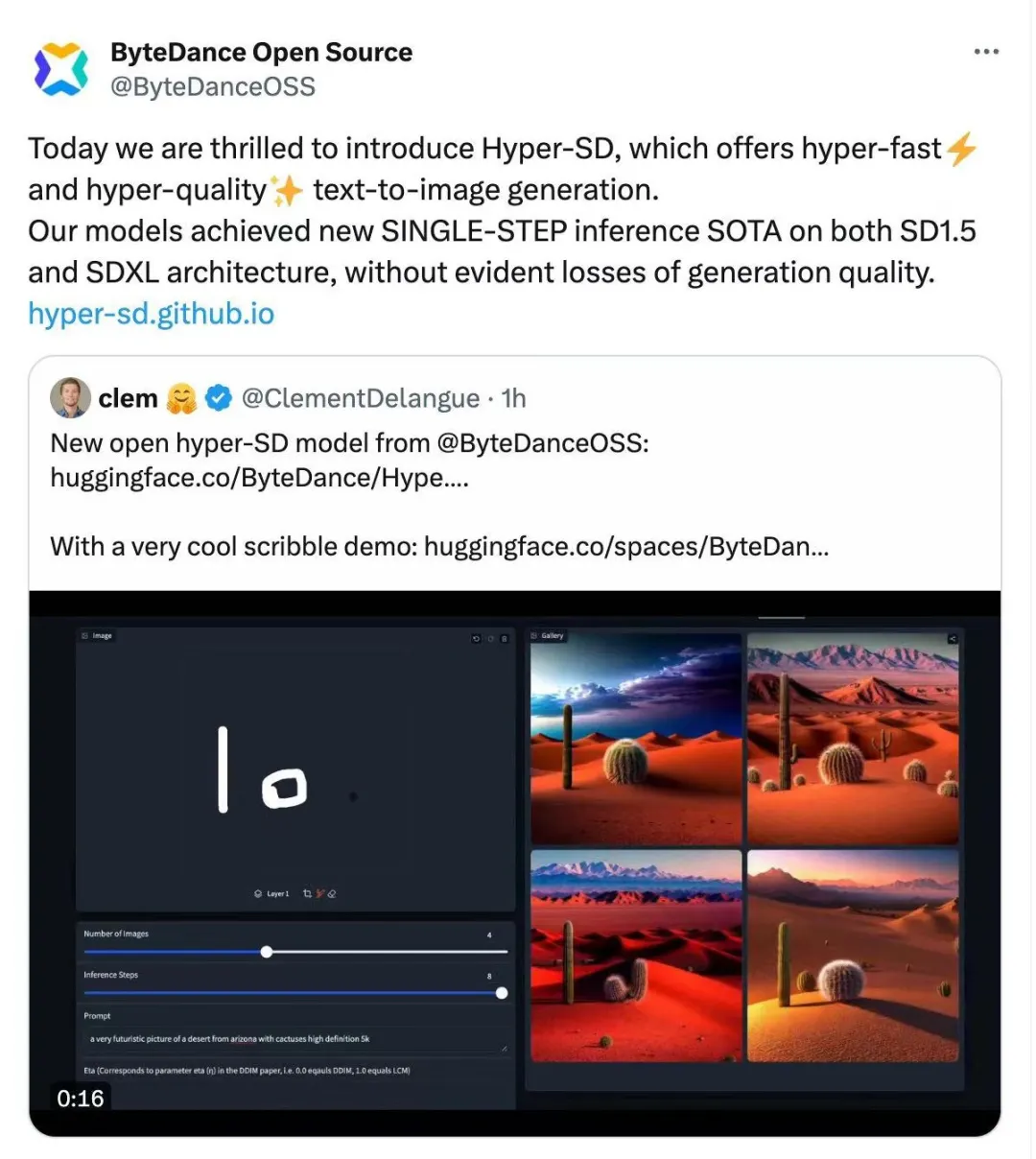
加速扩散模型,最快1步生成SOTA级图片,字节Hyper-SD开源了
加速扩散模型,最快1步生成SOTA级图片,字节Hyper-SD开源了最近,扩散模型(Diffusion Model)在图像生成领域取得了显著的进展,为图像生成和视频生成任务带来了前所未有的发展机遇。尽管取得了令人印象深刻的结果,扩散模型在推理过程中天然存在的多步数迭代去噪特性导致了较高的计算成本。
来自主题: AI技术研报
8737 点击 2024-04-25 17:13
 搜索
搜索
最近,扩散模型(Diffusion Model)在图像生成领域取得了显著的进展,为图像生成和视频生成任务带来了前所未有的发展机遇。尽管取得了令人印象深刻的结果,扩散模型在推理过程中天然存在的多步数迭代去噪特性导致了较高的计算成本。

提出图像生成新范式,从预测下一个token变成预测下一级分辨率,效果超越Sora核心组件Diffusion Transformer(DiT

Diffusion 不仅可以更好地模仿,而且可以进行「创作」。扩散模型(Diffusion Model)是图像生成模型的一种。有别于此前 AI 领域大名鼎鼎的 GAN、VAE 等算法,扩散模型另辟蹊径,其主要思想是一种先对图像增加噪声,再逐步去噪的过程,其中如何去噪还原图像是算法的核心部分。而它的最终算法能够从一张随机的噪声图像中生成图像。

没有谁能一直称王,但加上前缀谁都有称王的机会。AI 文生图,还能玩出什么新花样?在这片群雄割据的红海,头部被 Midjourney、DALL·E、Stable Diffusion 等占据,其余还能让人眼前一亮的产品并不多。然而,仍有黑马杀出:Ideogram,前 Google 工程师创立,硅谷 AI 大神投资,去年 8 月面世,2 月底发布了最新的模型。

Stable Diffusion 3 还没全面开放,这家公司的代码生成模型先来了。本周一,Stability AI 开源了小体量预训练模型 Stable Code Instruct 3B。

3D 生成领域迎来新的「SOTA 级选手」,支持商用和非商用。Stability AI 的大模型家族来了一位新成员。昨日,Stability AI 继推出文生图 Stable Diffusion、文生视频 Stable Video Diffusion 之后,又为社区带来了 3D 视频生成大模型「Stable Video 3D」(简称 SV3D)。

很快啊,“文生图新王”Stable Diffusion 3的技术报告,这就来了。

在众多前沿成果都不再透露技术细节之际,Stable Diffusion 3 论文的发布显得相当珍贵。

Stability AI放出了号称能暴打闭源模型的Stable Diffusion 3的技术报告,采用DiT构架的新模型在灵活性和性能上都达到了新的高度。

最近,OpenAI 视频生成模型 Sora 的爆火,给基于 Transformer 的扩散模型重新带来了一波热度,比如 Sora 研发负责人之一 William Peebles 与纽约大学助理教授谢赛宁去年提出的 DiT(Diffusion Transformer)。